Consensus in Distributed Systems
When you want to create a global, censorship-resistant supply of digital money, you need to build it on a distributed system. Using a distributed system removes the need for a central party being in control.
Distributed computing is an area of computer science that specifically studies distributed systems.
Although such distributed systems have many advantages, they also come with their very own challenges - one is reaching consensus among its participants.
We want to show you what a distributed system does, what challenges it poses, and how these challenges are addressed.
Bitcoin introduced the Nakamoto Consensus, an innovative method allowing all peers on the network to agree on a single version of the blockchain.
What is a Distributed System?
Let us first define a distributed system:
A distributed system is a set of processes, distributed across many locations, trying to achieve a common goal through coordination and communication via messages.
Now let’s take this apart
The set of processes are different participants of the network.
Each computer - or node - on the network that runs the client is a single process within the distributed system. The system’s common goal can be to exchange files (e.g. BitTorrent) or to enable a digital form of money (e.g. Horizen or Bitcoin).
The latter is what we will focus on.
The processes are separated and executed independently on each computer, but the system acts as one whole. In order to achieve one cohesive system, individual parts need to communicate and update each other.
This is done via messages that, in the context of a blockchain, are mostly transactions transferring money.
But why do we need a distributed system to run a blockchain?
Firstly, most blockchains strive for global participation, and therefore require a communication network that can operate globally. Additionally, distributed systems are more reliable as they don’t have single points of failure.
Challenges in Distributed Computing
While peer-to-peer networks come with unique advantages, they also have challenges that need to be addressed:
- Concurrency means that the individual processes, running on the nodes of the network, simultaneously execute the same program. Some level of coordination is necessary for them to reach their shared goal.
- There is no global clock that can keep all participants in sync. A mechanism that allows the synchronization of nodes is needed.
- An independent failure of the constituents may occur. Servers can crash or the internet connection can temporarily break down. A mechanism to make the system fault-tolerant is needed.
- Messages need to be passed around, to achieve coordination and synchronization. A broadcasting mechanism is needed to facilitate the necessary communication between nodes.
We will mostly be concerned with the last two challenges:
- Making the system fault-tolerant
- and having the processes communicate efficiently
Building a Fault-Tolerant Distributed System
Failures can broadly be categorized into one of the following three cases:
Crashes, Omission or Byzantine behavior
- In a crash-fail, a component of the system stops working completely. This might be because of an internet outage or because a node operator is restarting their machine.
- Omission means that a node sends a message which is not received by its peers.
- Lastly, Byzantine failures refer to random behavior that can be guided by malicious intentions or simply malfunctioning clients. They are the hardest failures to address as they are random by definition.
- Any malicious actor trying to attack the system by deviating from the protocol would be an example of a Byzantine failure.
Handling Byzantine behavior is difficult because parties can be online or offline and can lie, coordinate or act arbitrarily.

The system should be fault-tolerant, in that it continues to work regardless of failures in its components. Depending on which type of failures it can handle, the distributed system can be classified as either simple fault tolerant or Byzantine Fault-Tolerant.
A simple fault tolerant system handles the first two types of failures, crash and omission.
A Byzantine Fault-Tolerant system handles all three types of failures and keeps functioning even in the presence of malicious actors trying to disrupt it through Byzantine behavior.
Accounting for Different Levels of Network Robustness
When designing a distributed system, one has to make certain assumptions about the components. When it comes to broadcasting mechanisms, spreading messages across the network, one has to account for the reliability of the underlying peer-to-peer network.
The system needs to be robust enough to handle communication failure. If you assume a stable network, designing the system will be a lot easier, but the result won’t be very robust in the real world.
If you base your system design on the assumption that certain components won’t work as planned, the system design becomes much more challenging, but the result will be robust - or even better - antifragile.
There are three standard models for how well the message propagation works, which affect the system design to a great extent.

When you assume synchronous message propagation, all messages are received within some fixed and known amount of time by the receiver.
If message propagation is partially synchronous, messages are assumed to be delivered in bounded time, so within a fixed timeframe, but the bound is unknown.
Asynchronous message delivery assumes that messages might never reach their destination, are duplicated, or are received in a different order than sent.
As you can imagine, building a distributed system, which relies on communication, on an asynchronous network poses the greatest challenge. Mastering this challenge will yield a highly robust network.
To recap: We want to use a distributed system for its resilience and lack of single points of failure. Our system needs to handle the individual components failing, through either crash, omission or Byzantine behavior.
It also needs to handle the communication in an unreliable environment, so at least a partially synchronous network, where delivery time is bound, but unknown or - even better - an asynchronous environment, where one cannot be sure if messages ever arrive.
Different Assumptions Lead to Different Designs
Depending on which assumptions one uses to design a system, the result can display different levels of fault-tolerance. If the system assumes that all nodes either function and follow the protocol or crash-fail, the system is Simple Fault-Tolerant.
Depending on the context, this might be a sufficiently safe assumption. In a permissioned network, e.g. within the production line of a factory, one rarely has to account for malicious behavior.
A system that can also handle the random and malicious behavior of a Byzantine participant, is called Byzantine Fault-Tolerant (BFT). We want blockchains to be permissionless infrastructure for value transfer, which anybody can join at will. Hence, we have to account for malicious actors that will try to game the system. This means we do require a BFT consensus mechanism.
Byzantine, Rational, and Altruistic Actors
Sometimes you might also hear the term BAR-FT - Byzantine-Altruistic-Rational Fault Tolerance.
The BAR part refers to the different actors one can find in an open network. Peers in a permissionless network can be one of three things: Byzantine, rational, or altruistic.
- We defined Byzantine behavior earlier as random behavior that deviates from the protocol. This term is mostly used to describe the actions of an attacker.
- Rational actors will follow the protocol, as long as it is the most profitable strategy for them. If deviation from the protocol is more profitable, they will deviate to maximize their profit.
- Altruistic or honest actors will do what is best for the network, even if a different strategy would mean a personal advantage for the individual.
As we said before, building a system under the assumption that communication between nodes works flawlessly makes things significantly easy.
The same goes for assumptions on the network participants: assuming honest behavior for all peers will make system design a lot easier, but the system won’t last very long in the real world.
The holy grail of consensus mechanisms is to achieve consensus in a group that includes malicious actors, built on an unreliable network.
Using the terminology we just introduced, this is described as building a Byzantine Fault-Tolerant system in an asynchronous environment.
Defining Consensus
Before we move on, we need to define what “achieving consensus” means.
Although you might have an intuition for what consensus is, let’s create an exact definition so that we can evaluate potential candidates for a suitable consensus mechanism.
To establish a clear definition, let’s start with a simplified blockchain - the finite state machine.
It is a mathematical model of computation that removes the complexity of the blockchain and reduces the functionality to the core.
The Replicated State Machine
A finite state machine starts in an initial state and can only be in a single state at any given time.
A state transition happens in response to some external event. The state transition logic defines how a new state is computed based on a given external event.
An event, a message, or a transaction in this model is atomic: it either succeeds or fails.
In the context of distributed systems, one speaks of replicated state machines when all nodes on the network are identical copies of one another.
A blockchain is similar to a replicated state machine in that it also starts with an initial state - the genesis block.
The external events in a blockchain are mostly transactions between users. State transitions happen in intervals - one transition with each new block.
The Safety and Liveness Criterion
Consensus among the individual nodes of a replicated state machine is defined via two properties: liveness and safety.
- Liveness (or termination) means that all non-faulty nodes eventually compute a new state according to the state transition logic when an external event happens. In simple terms it means, the system doesn’t halt, and always reacts to events.
- Safety (or agreement) means that all non-faulty nodes transition to the same state after a given external event. This means, all nodes will be in sync eventually.
All non-faulty nodes reach a new state eventually (liveness), and all nodes agree on a new block (safety). With this new terminology, we can refine our definition of the holy grail of consensus mechanisms:
Building a Byzantine Fault-Tolerant consensus mechanism that works in an asynchronous environment and can guarantee safety as well as liveness is the holy grail in distributed computing.
Alright, now we know what consensus means and what kind of failures a robust consensus mechanism has to tolerate. But how do we get there?
The Early Days of Distributed System Design
While one might think all this is cutting-edge stuff from the 21st century, people have been studying distributed consensus for decades!
A milestone in the exploration of distributed computing was a paper from 1985 written by Fischer, Lynch and Paterson with the title “Impossibility of Distributed Consensus with One Faulty Process”.
It concluded that a single faulty process can make it impossible to reach deterministic consensus in an asynchronous environment.
We already know that asynchronous refers to the network being unreliable. But what does deterministic mean in this context?
Deterministic consensus means every state transition has instant finality:
When nodes compute a new state (liveness) and agree on it (safety) they can be 100% certain the new state is final and will never change again.
The findings of Fischer, Lynch and Paterson hold, meaning one has two options to reach Byzantine Fault-Tolerance:
One can either assume a synchronous network or one can pursue a non-deterministic form of consensus.
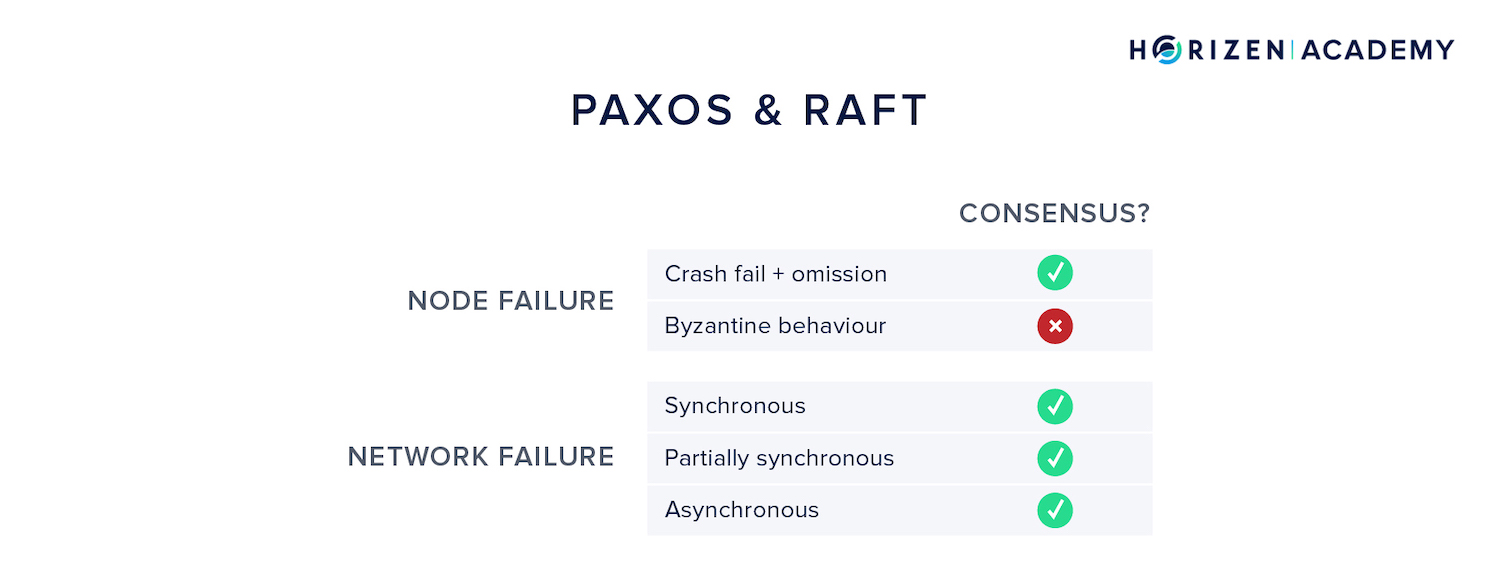
Paxos
One of the early attempts to reach distributed consensus was the Paxos protocol family.
Paxos achieves consensus in an asynchronous setting, but can not handle Byzantine behavior. Transitioning from one state to another requires a lot of communication overhead.
The transition logic happens in three steps comprising a preparation phase, an accepting phase, and lastly a learning phase.
If a transition fails or halts, there is a timeout mechanism after which the system restarts. Because of the multi-step process of state transitions, Paxos is hard to understand and hard to implement.
Raft
Raft is another consensus mechanism published in 2013. It set out to be easier to understand and implement than Paxos.
It also uses timeouts in case a state transition fails and can therefore handle asynchronous environments. But just like Paxos, it fails to achieve consensus with Byzantine actors and is only simple fault-tolerant.
What we can learn from Paxos and Raft is that handling Byzantine behavior in an asynchronous environment is a hard problem.
The Byzantine Generals Problem
The challenge of handling Byzantine actors is widely researched.
It is referred to as the Byzantine Generals Problem in a paper by Lamport, Shostak and Pease.
A major contribution of their work was precisely defining the number of Byzantine Nodes a system can handle while still being able to reach consensus.
The result is less than a third of all nodes n:

The argumentation for getting this result is straightforward:
- If x is the number of Byzantine nodes, the system must work in case they are unresponsive, so with (n-x) nodes.
- Now it is possible that the unresponsive nodes suffered from crash-faults and all x Byzantine nodes are still live. In this case (2x) nodes are either not responsive or Byzantine.
- Because a majority of honest nodes is required to achieve consensus, we need a total of n = 3x + 1 nodes, which in turn means a maximum of nodes can be Byzantine for the system to keep working.
What we have learned from looking at the Byzantine Generals Problem is that the threshold for the maximum share of Byzantine participants on the network is rather low, clocking in at one third of the total node count.
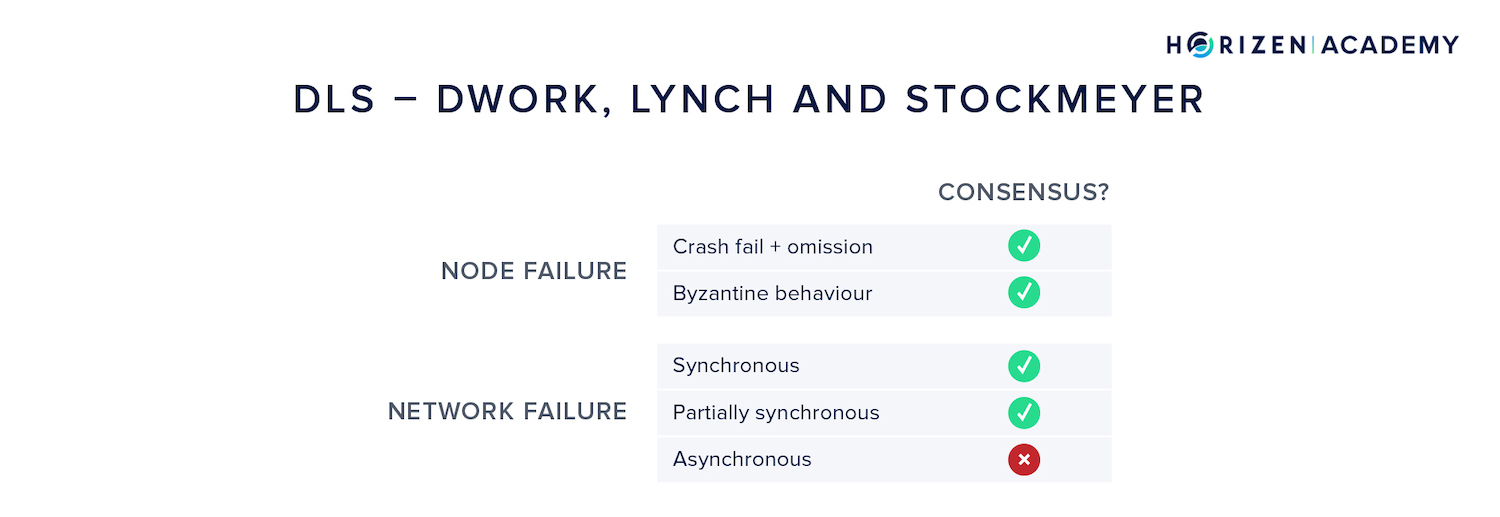
DLS
When we talked about the different assumptions for the network reliability, we mentioned the partially synchronous model, where messages are assumed to be delivered in bounded time, but the bound is unknown.
This model was introduced with the DLS algorithm after Dwork, Lynch and Stockmeyer. It also introduced the terms liveness and safety that we already talked about.
Liveness is the property of the system continuing to work in case of failures, while safety is the agreement of the network on a single state.
The DLS algorithm contributed greatly to the development of consensus research, in that it established a new network model (partial synchrony) and achieved safety and liveness in a Byzantine environment. However, it failed to do so in an asynchronous setting. It also came with a non-starter that prevented it from being implemented in a meaningful way.
It assumed a synchronized clock between all nodes, an assumption that is not realistic in a permissionless system.
pBFT - Practical Byzantine Fault-Tolerance
In 1999, yet another consensus algorithm was published - practical Byzantine Fault-Tolerance (pBFT) by Castro and Liskov.
It got pretty close to achieving the final goal:
Handling malicious actors in an unreliable network while ensuring safety and liveness.
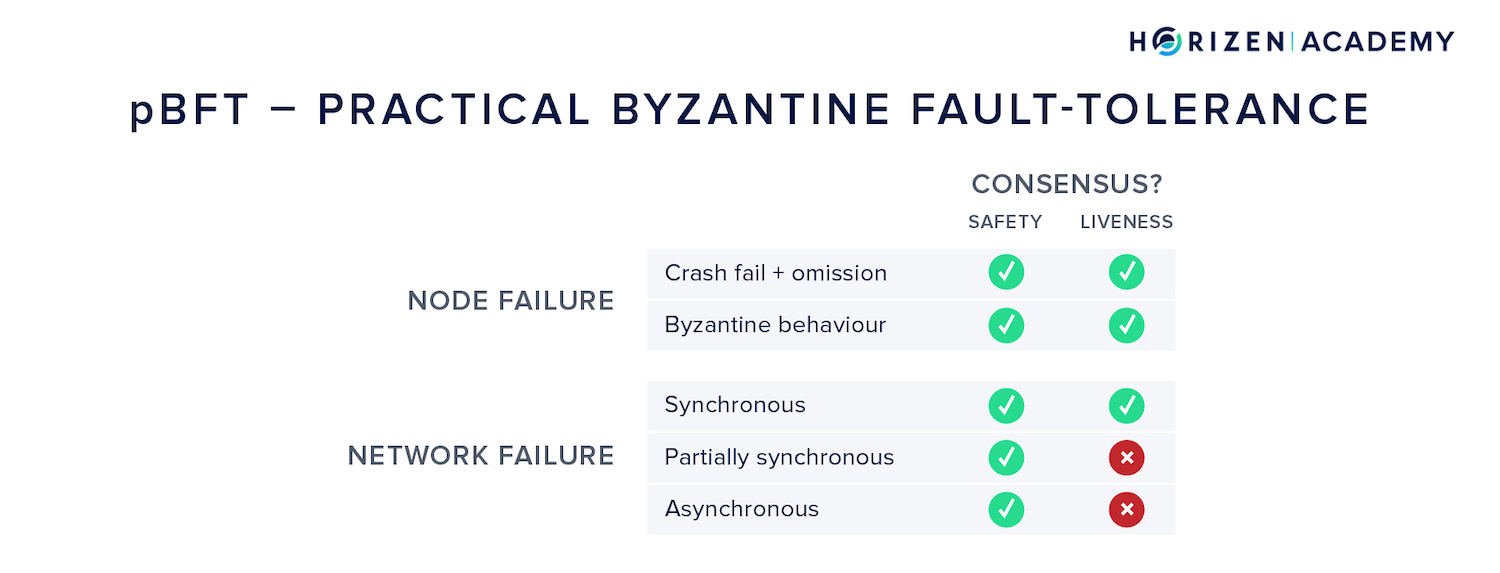
pBFT can guarantee safety under all circumstances (assuming a maximum of Byzantine nodes), but it relies on the synchronous model to achieve liveness.
Put differently, in an unreliable communications network the system might halt.
pBFT also suffers from scalability issues:
The number of messages needed to keep the network in sync grows exponentially with the number of nodes. It is therefore impractical for public blockchains.
Changing the Definition of Consensus
The problem of achieving consensus reliably has obviously been solved, otherwise we wouldn’t be here. But how did Satoshi do this?
The important leap was moving away from a deterministic definition of consensus. While some might argue this is moving goalposts, in practice it is what makes public blockchains work - a non-deterministic definition of consensus.
Using determinism means, that each new state is decided on by all nodes in a binary fashion: correct or false.
The consensus mechanism, therefore, had nodes agree on some fixed new state.
In the non-deterministic model, the consensus mechanism lets all nodes agree on the probability of a new state being the global state. Remember that a new state in a blockchain is reached when a new block is added to the chain.
When a new, valid block is proposed, nodes can be fairly certain that it will stay valid, but they do not know for sure. With each additional state transition - in our context each new block or confirmation - the probability of the state being safe slowly but surely approaches 1.

It is important to note, that the Nakamoto Consensus cannot provide finality. Although the probability of a block being reversed approaches 0 the more confirmations it has, it never actually equals zero.
In practice, this property leads to the receiver of a transaction waiting for a few confirmations, until the funds are considered received. It also limits the possible approaches to scalability.
Sharding is an approach from the traditional database world where the data is partitioned into several shards. Without finality, this tactic becomes infeasible.
Nakamoto Consensus
But wait, how does the Nakamoto consensus actually achieve consensus?
In the mechanisms we outlined above you can break down the process of achieving consensus to a proposer suggesting a state transition and a group of acceptors coordinating to either accept or decline the proposed state.
This coordination displays the characteristics of a ballot. A shortened Demiro Massessi quote reads:
“In one way or another, […] consensus algorithms boil down to some kind of vote […].” - Demiro Massessi
Nakamoto consensus with Proof-of-Work (PoW) does not require a leader (proposer) selection of any kind. Anybody is free to start mining and thereby proposing blocks. The consensus is based on who can find a nonce, that hashed together with the proposed block header, yields a block hash below the current target value.
The chance of finding such a nonce is proportional to the relative hash power - or computing power - a given miner controls. This means state transitions are voted on with computational power, and the state transition logic is defined by the target a valid block hash has to meet.
At this point, we would like to quote Demiro in full:
“The main difference between consensus mechanisms is the way in which they delegate and reward the verification of transactions. […] In one way or another, blockchain consensus algorithms boil down to some kind of vote where the number of votes that a user has is tied to the amount of a limited resource that is under the user’s control.” - Demiro Massessi
The limited resource in the case of the traditional Nakamoto Consensus using Proof-of-Work is computing power.
The genius part was adding an incentive system on top of the consensus mechanism. Participants spend real-world resources (computations = electricity) on achieving consensus within the network.
By rewarding the miner of each block with the block subsidy, there is an incentive for rational actors to perform this task. Once the native currency of the network has a value greater than zero, the network can pay for its own maintenance without anybody being in charge.
PoW + Longest Chain Rule = Consensus
The consensus mechanism is composed of two parts.
- One is the Proof-of-Work component that facilitates a type of voting and is Sybil-resist.
- The other part is the longest chain rule or heaviest chain rule, both describing the chain with the most cumulative computational work.
The longest chain rule is applied in case two miners find valid blocks at roughly the same time - a tie because both blocks are valid according to the protocol.
The other miners start building on the block they received first but keep the second candidate in memory. Different miners can have different views on which block came first, depending on their geographical location and their connectivity in the network graph.
The tie is broken once the next block is found.
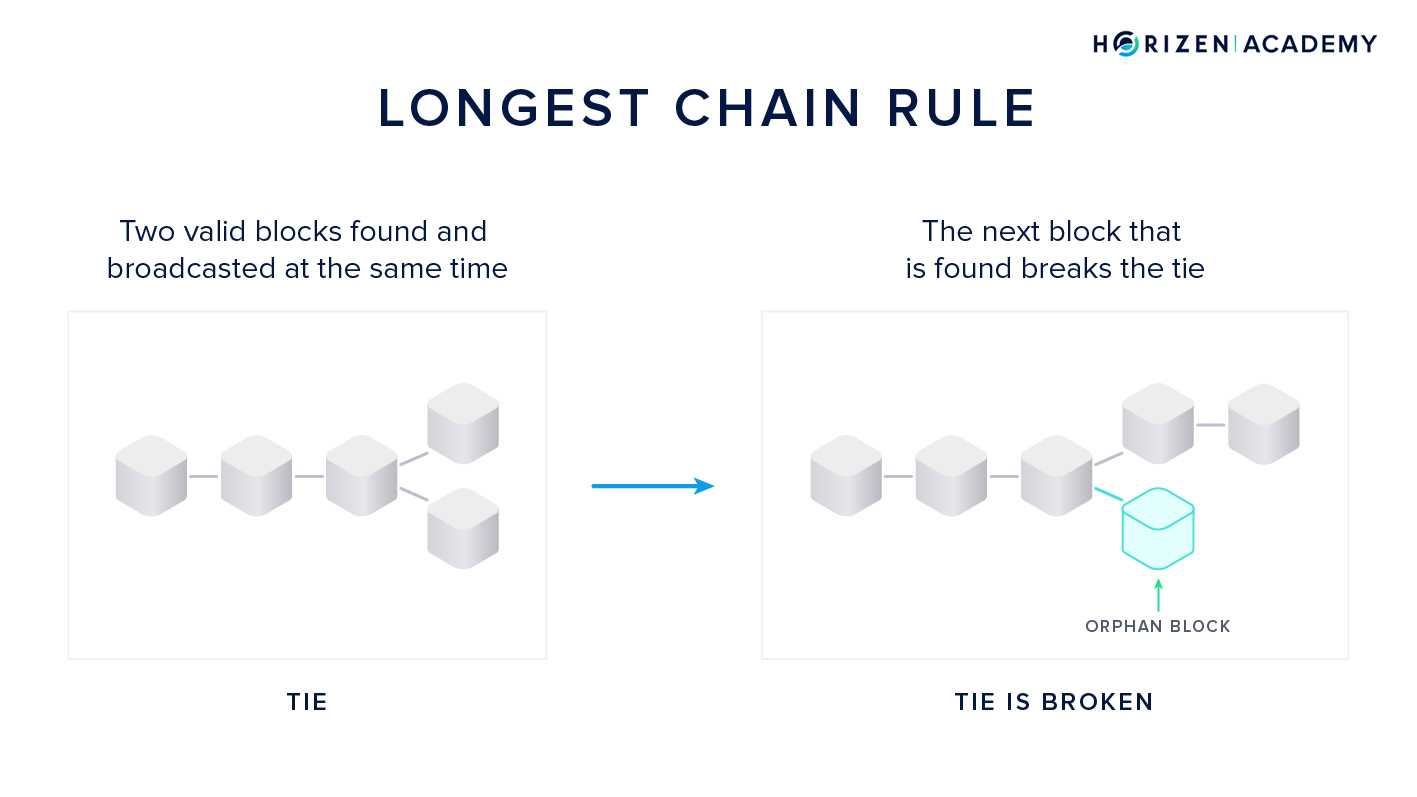
The resulting chain of state transitions - the blockchain - does not only entail the chronological order of events, but also proves that it came from the largest pool of computing power.
Nakamoto Consensus not only attempts to solve the Byzantine Generals Problem, but also raises the bar for Byzantine tolerance. Instead of being able to handle roughly a third of participants being Byzantine, it can handle almost half of the network being malicious.
- Sometimes, this is referred to as (2x + 1) resilience in the case of Nakamoto consensus vs. (3x + 1) resilience in most other cases.
This share is defined via the amount of computational power rather than nodes on the network.
PoW and its relatives can be seen as Sybil-resistance mechanisms. In a Sybil Attack, a malicious party creates a large number of centrally controlled identities and tries to achieve certain, mostly malicious, goals by exerting influence through these fake identities.
Online voting is the most intuitive example of a situation, where many fake identities can be used to game the results. Sybil-resistance mechanisms prevent this by tying an entity's voting power to a scarce resource that is harder to obtain than fake user accounts or IP-addresses.
In the case of PoW, this scarce resource is computing power. The longest chain rule is the “actual consensus mechanism” that has nodes agree on a single version of truth in case several candidate versions exist.
Summary - Consensus in Distributed Systems
We looked at the challenges of achieving consensus in a distributed setting. The consensus mechanism has to tolerate malicious actors (Byzantine fault tolerance) and it needs to handle a network providing unreliable communication (asynchronous network).
We defined liveness, as the property of all nodes eventually computing a new state based on external events. Put differently, the system doesn’t stall. In the context of blockchains, liveness means that all valid transactions will eventually end up in the blockchain.
This is closely related to the property of censorship resistance.
Next we defined safety as all non-faulty nodes agreeing on new states. We learned that Nakamoto Consensus does not provide finality, but rather an increasing probability of a state being final with a growing number of confirmations.
Therefore safety is closely related to the immutability property of blockchains. With every new block, a blockchain demonstrates liveness, and safety is achieved after a few confirmations.
Nakamoto Consensus is brilliant in that it defined consensus in a novel way: non-deterministic. A new block isn’t necessarily agreed upon by all nodes at the time it is mined, but the more blocks are built on top of it, the more certain all participants can be that it will stay.